
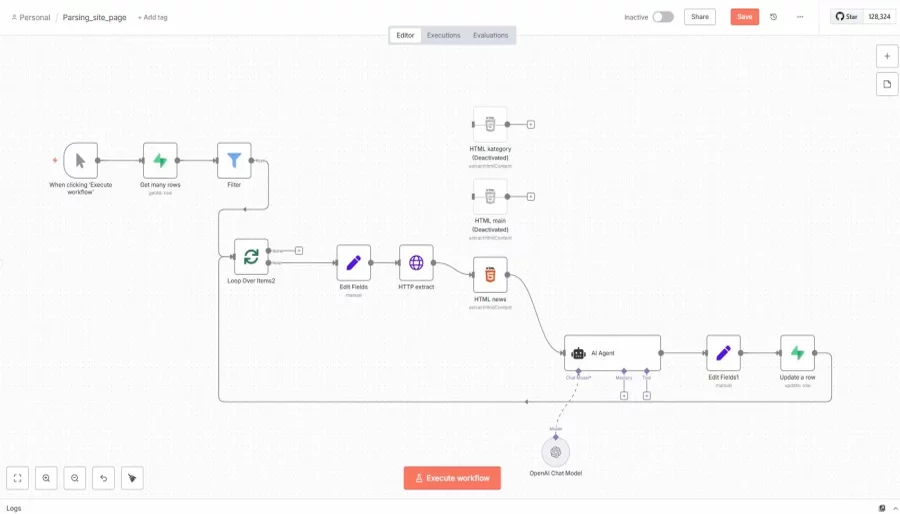
Наш Workflow автоматизирует процесс парсинга, очистки и обработки информации с сайта, используя AI-технологии, и сохраняет результаты в базу данных Supabase. Такой подход повышает эффективность работы с большими объемами данных и обеспечивает их актуальность.
Этот Workflow логическое продолжение автоматизации Загрузка структуры сайта CMS DataLife Engine в Supabase.
Логика работы: забираем ранее загруженный список страниц, очищаем от лишних данных, обрабатываем с помощью AI агента и загружаем в ту же таблицу базы данных.
Описание нод workflow
Get many rows - забираем список страниц из базы данных
Filter - в базе данных страницы разделены на katalog, static, news. Отфильтровываем нужное значение, это понадобится в очистке html кода т.к. селекторы на страницах могут быть разные.
Loop Over Items - цикл обработки страниц
Edit Fields - присваивается переменная url страницы и id записи
HTTP extract - парсинг страницы
HTML news (HTML main, HTML kategory) - очистка страницы по селекторам. Это одинаковые ноды, но разные по настройкам селекторов - для категории, для статических страниц, для новостей
AI Agent - обрабатывает полученный текст
Edit Fields1 - присваиваются переменные Заготовок, Текст, ID записи
Update a row - обновление той же таблицы базы данных, дозапись в соответствующие поля
После того, как в нашей базе данных есть вся информация по каждой странице сайта, то далее ее можно уже обрабатывать для дальнейшего использования, например выгружать в векторную базу данных.
Код sql запроса для создания таблицы:
CREATE TABLE sitepage ( id bigint NOT NULL, linkurl text, vid text, title text, fulltext text, imgurl text);